四位数字验证码识别¶
这是给 BenderBlog/traintime_pda 做的功能,可以自动通过学校某些网站的验证码,给 app 用户更好的体验。这也是我第一次自己做数据集,训练模型,并且用在正经的地方()。代码开源在 stalomeow/captcha-solver。
技术选型¶
因为是图像相关的任务,所以选择卷积神经网络。接着,我找了下 tensorflow 和 pytorch 的 flutter 插件,对比下来 tflite_flutter 比较好,它是 tensorflow 官方维护的,并且支持的平台也最多。
电费验证码¶
电费验证码可以在 https://payment.xidian.edu.cn/authImage 获取,分辨率是 200x80。

这个验证码比较人性化,相对好做。一开始,我将整个图片转为灰度扔给 CNN 识别,但效果不好,模型也很大。后来,我把验证码的四个数字拆开,CNN 每次只识别一个数字,这样效果很好。这个验证码只要水平 4 等分就能把数字拆开。
模型很小,只有不到 130KB,不会显著增加 app 包体,也方便在各种设备上运行。
keras.models.Sequential([
keras.layers.Conv2D(16, (3, 3), activation='relu', input_shape=input_shape),
keras.layers.MaxPooling2D(pool_size=(2, 2)),
keras.layers.Conv2D(32, (3, 3), activation='relu'),
keras.layers.MaxPooling2D(pool_size=(2, 2)),
keras.layers.Conv2D(32, (3, 3), activation='relu'),
keras.layers.MaxPooling2D(pool_size=(4, 4)),
keras.layers.Flatten(),
keras.layers.Dense(64, activation='relu'), # 适当减少神经元
keras.layers.Dropout(0.3), # Dropout 防止过拟合
keras.layers.Dense(util.get_captcha_num_classes(type), activation='softmax')
])
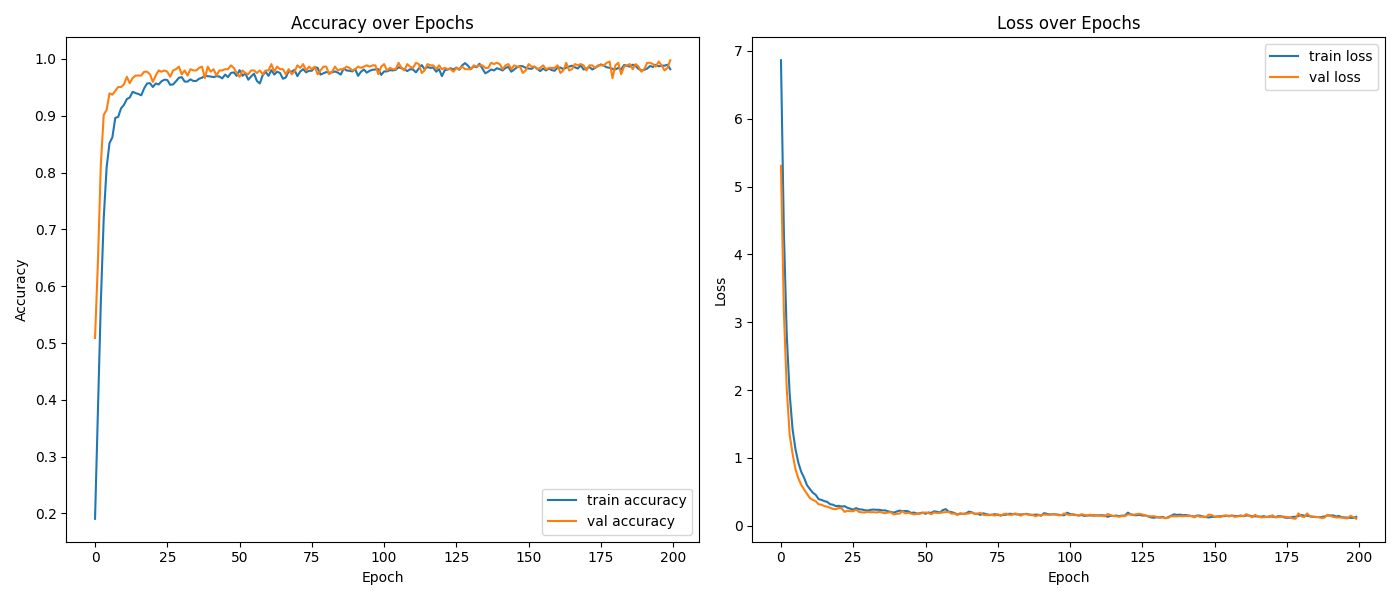
用几百张图片训练了 1 分钟左右,模型很快就收敛了。
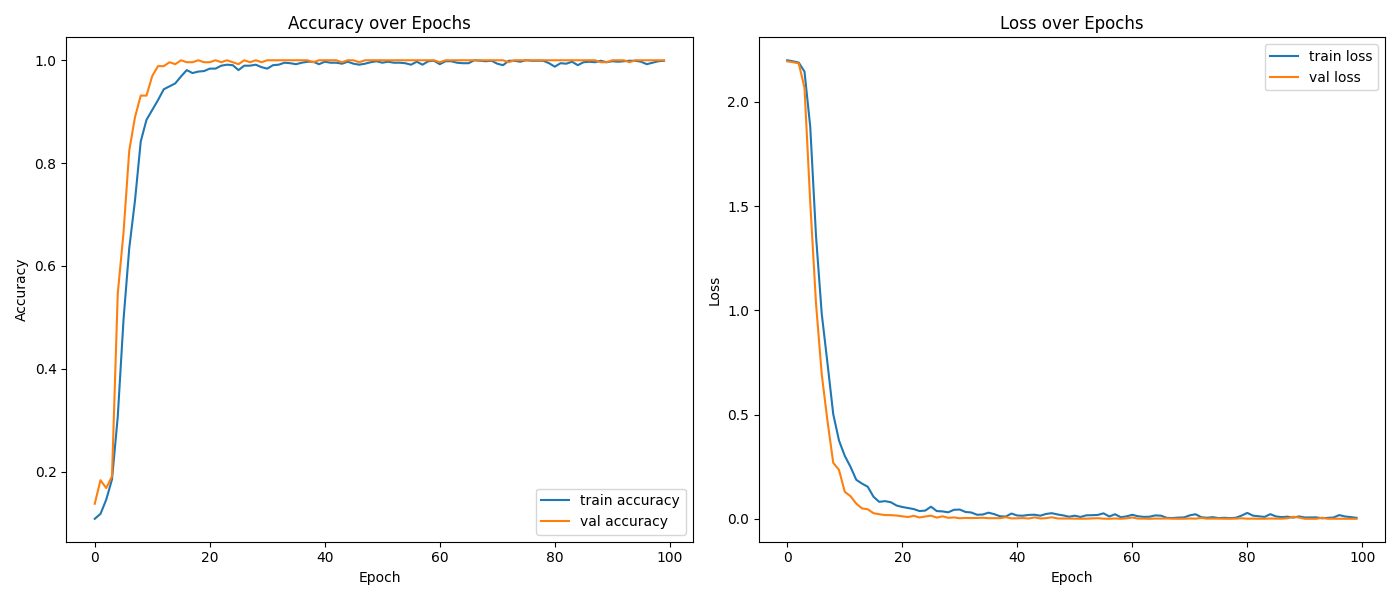
数据集是自制的,专门针对学校的验证码。工具是用 tkinter 写的,输入验证码后回车,就能自动切分数字并打上标签保存,然后自动获取下一个验证码并 focus 输入框。效率非常高,甚至有点上头。

模型测试工具基本复用了上面的代码,可以测试模型在实际场景下的表现。下图输入框里的数字是模型预测的。
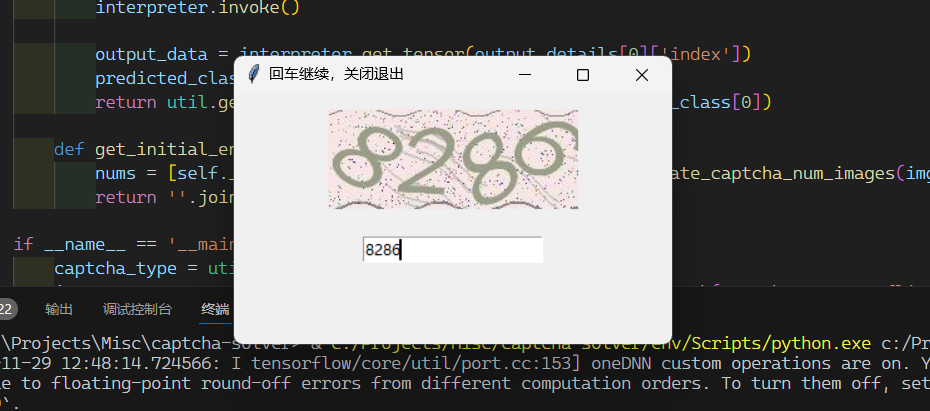
自服务验证码¶
自服务验证码可以在 https://zfw.xidian.edu.cn/site/captcha 获取,分辨率是 90x34。

这个验证码不好识别,数字挤在一起,尤其是数字 1,有时候我自己都会输错。这种情况只能换一张验证码。

思路是将它转化为电费验证码的形式,然后尝试复用旧的模型。
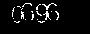
反色再二值化能去掉大部分噪声,但数字很多地方断开了不方便识别。不过,通过这张图能算出数字的包围盒。如果包围盒宽度小于一个阈值,就认为数字都挤在一起,放弃预测。将灰度图中包围盒内的部分上采样为 200x80(电费验证码的分辨率)。上采样类似 bilinear,但不是对四个像素插值,而是取四个像素的最小值,相当于一边放大一边做 形态学腐蚀。
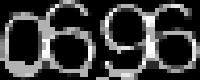
套用电费验证码模型的结果不理想,我又重新训练了一个模型。训练时发现过拟合问题比较严重,所以改用更大的 dropout rate,并加上 L2 正则化。
keras.models.Sequential([
keras.layers.Conv2D(16, (3, 3), activation='relu', input_shape=input_shape),
keras.layers.MaxPooling2D(pool_size=(2, 2)),
keras.layers.Conv2D(32, (3, 3), activation='relu'),
keras.layers.MaxPooling2D(pool_size=(2, 2)),
keras.layers.Conv2D(32, (3, 3), activation='relu'),
keras.layers.MaxPooling2D(pool_size=(4, 4)),
keras.layers.Flatten(),
keras.layers.Dense(64, activation='relu', kernel_regularizer=keras.regularizers.l2(0.06)), # L2 正则化防止过拟合
keras.layers.Dropout(0.55), # Dropout 防止过拟合
keras.layers.Dense(util.get_captcha_num_classes(type), activation='softmax')
])
单个数字识别率大概是 97%,考虑到验证码各种奇奇怪怪的情况,以及切分数字的准确性,最后总识别率估计有 80% 就不错了。
文章推荐¶
推荐一篇类似的文章:基于CNN的四位数字验证码识别_四位验证码识别-CSDN博客。